AI Everywhere Is Not an Operating Model
Big Tech is currently pushing a culture of AI saturation. They are increasingly setting up their infrastructure to remove friction, push AI into every workflow, and let usage reveal the future. This is a rational approach, and works for discovery, but is not sufficient for long-term AI strategy. That is a result of something much harder.
Meta recently built an internal leaderboard ranking employees by AI token usage, intended to drive token adoption across the company, and they are not alone. The consensus enterprise AI playbook is becoming increasingly clear: remove friction to AI adoption, give employees essentially unlimited tokens, push AI into every workflow, and let the organization discover winning patterns through usage. Institutions are aggressively encouraging adoption, and quietly eliminating talent that seems unable or unwilling to make the shift.
While this is an aggressive bet, it is not striking in and of itself. Many of these companies have deep pockets and excellent revenues that can sustain this workflow for an extended period of time. What is striking is the absence of a standard operating model.
Due to the unprecedented rate at which the technology is evolving, this is partly understandable. The search space for the optimal operating model is expanding weekly - context engineering, prompt chaining, MCPs, RAG, agent frameworks, skills, the list goes on. Nobody knows yet which combination wins. And so the prevailing logic is: get people using it, reduce the cost of experimentation to near zero, and let the winning patterns emerge.
To most, this would seem like a rational exploration strategy, but it is not an operating model. Not yet.
The bet is not wrong
Before arguing against saturation as a strategy, it is worth being honest about why it makes sense.
When a technology is genuinely new, premature constraints kill discovery. You cannot know where value lives until people have tried things, and this has proven itself to be true over the past few years. The organizations that rationed AI access too early out of caution, governance anxiety, or simply slow procurement, paid a real cost. They are now behind, and catching up in an incredibly competitive market is increasingly challenging.
There is also a real adoption problem that needs to be considered. Changing how people work is a significant ask, especially with technology this novel and paradigm-shifting. Many of the most prominent voices in software spent years as loud public skeptics of AI before quietly (and then very publicly) changing their position. What changed them was continued use of the technology, and eventually seeing it work in ways that made their lives meaningfully easier.
The saturation bet is designed to manufacture that moment at scale. Make the models cheap to access, remove token anxiety, and ask people to bring AI into every workflow they can. This will recreate the conditions for the conversion experience to happen quickly, and at scale.
The first mistake is rationing AI too early, and the saturation playbook is a reasonable approach to avoiding that mistake.
The hidden assumption
There is, however, an implicit premise hidden inside the saturation playbook that requires deeper examination: more usage will naturally reveal better ways of working.
On the surface this sounds intuitive as more attempts mean more data, and more data means better pattern recognition. The hypothesis is that eventually, the organization learns what good looks like.
But this assumes that quantity of attempts produces quality of judgment, when it does not. At least not automatically. Usage reveals what is possible, but it does not select for what is valuable. Those are different problems, that require different interventions.
The question the saturation playbook cannot answer on its own is: good by what standard?
Revenue is a good answer, and most leaders would say so. But revenue is a lagging aggregate indicator, and it is difficult if not impossible to directly attribute specific workflows to downstream revenue. We need to identify standards that operate at the work layer, and not the results layer.
What saturation actually produces
What saturation produces at scale is volume: more drafts, more analyses, more recommendations, more internal tools, more agents completing tasks. What it does not produce is a selection mechanism to determine which of those outputs deserves trust, action, or scale, and which should be deleted.
It is becoming increasingly clear that, by and large, AI saturation improves individual outputs. A well-prompted analysis is often sharper than what the same person would have produced alone and at the individual level, the productivity gains are real.
But the problem is organizational. Better individual outputs do not automatically aggregate into better decisions, clearer priorities, or sounder strategy. The gap between improved artifacts and improved decision-making is exactly where the operating model problem lives.
This is the structural weakness. AI does not change the operating model, but instead increases the volume of attempts against the existing one. If those underlying workflows are sound, that is genuinely useful. If they are not (and in most large organizations, many are not) saturation accelerates the wrong things at higher speed, with a layer of polish that makes them harder to challenge.
The bottleneck moves downstream
When the cost of generation collapses, the constraint moves downstream.
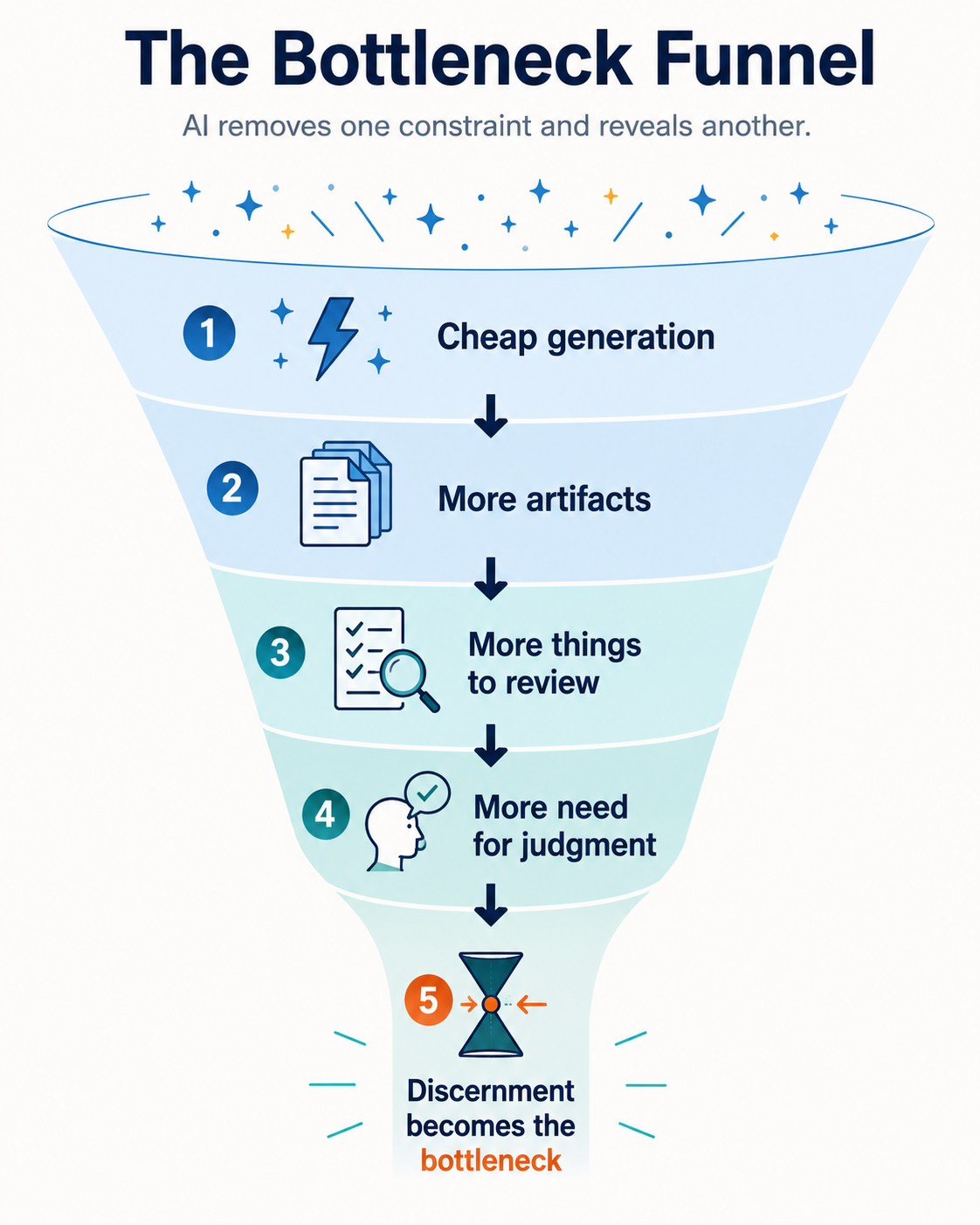
Every organization that has deployed AI broadly is now running an experiment in what happens when output volume outpaces judgment capacity. The symptoms are recognizable: inboxes full of AI-generated summaries nobody reads, strategy decks that sound rigorous but recommend nothing, agents that complete tasks without anyone being sure the tasks were worth completing.
As tokens become cheaper, judgment becomes the scarce infrastructure.
This is a genuine organizational concern, and is a predictable structural consequence of what the saturation playbook produces at scale.
The five failure modes
It is important to note that the risk here goes significantly deeper than wasted compute. In fact for many companies, that is a rounding error. The real costs are subtler and more insidious.
Artifact inflation. As volume becomes a substitute for value, the organization produces more “work-like” objects than need to be meaningfully absorbed or acted on. People are busy generating, but nobody is sure what to do with what gets generated.
False confidence. AI makes weak thinking sound polished and executive-ready. The friction that used to signal low quality including rough prose, obvious gaps, and the effort required to produce something coherent, disappears. Bad ideas arrive well-dressed and are increasingly more difficult to refute.
Workflow preservation. Companies use AI to accelerate processes that should be deleted. Instead of asking whether a workflow is worth doing, they ask how AI can make it faster. This results in bad workflows being performed at higher speed, with an AI wrapper that makes them feel modern.
Accountability diffusion. More people can generate recommendations while fewer people own decisions. The organization gets more output and less ownership simultaneously. When an AI-assisted analysis turns out to be wrong, the question of who is responsible becomes genuinely hard to answer.
Taste collapse. When output gets cheaper, mediocre output becomes more abundant. Over time, the average quality of organizational thinking quietly declines. Importantly, people are just as capable, but the signal-to-noise ratio slowly shifts, as nobody takes the time and effort to determine what “good” looks like.
The hidden cost of unlimited AI is, ironically, attention.
The better model
The answer is not to constrain AI early as that forfeits the discovery value of saturation, and the organizations that went that route are already paying for it. The answer is to constrain deliberately, after exploration, with intention.
It helps to name where most companies currently stand:
Phase 1: Access — Can people use AI?
Phase 2: Usage — Are people using AI?
Phase 3: Standards — What does good output actually look like?
Phase 4: Deletion — What work should disappear entirely?
Phase 5: Redesign — How should the operating model change around what remains?
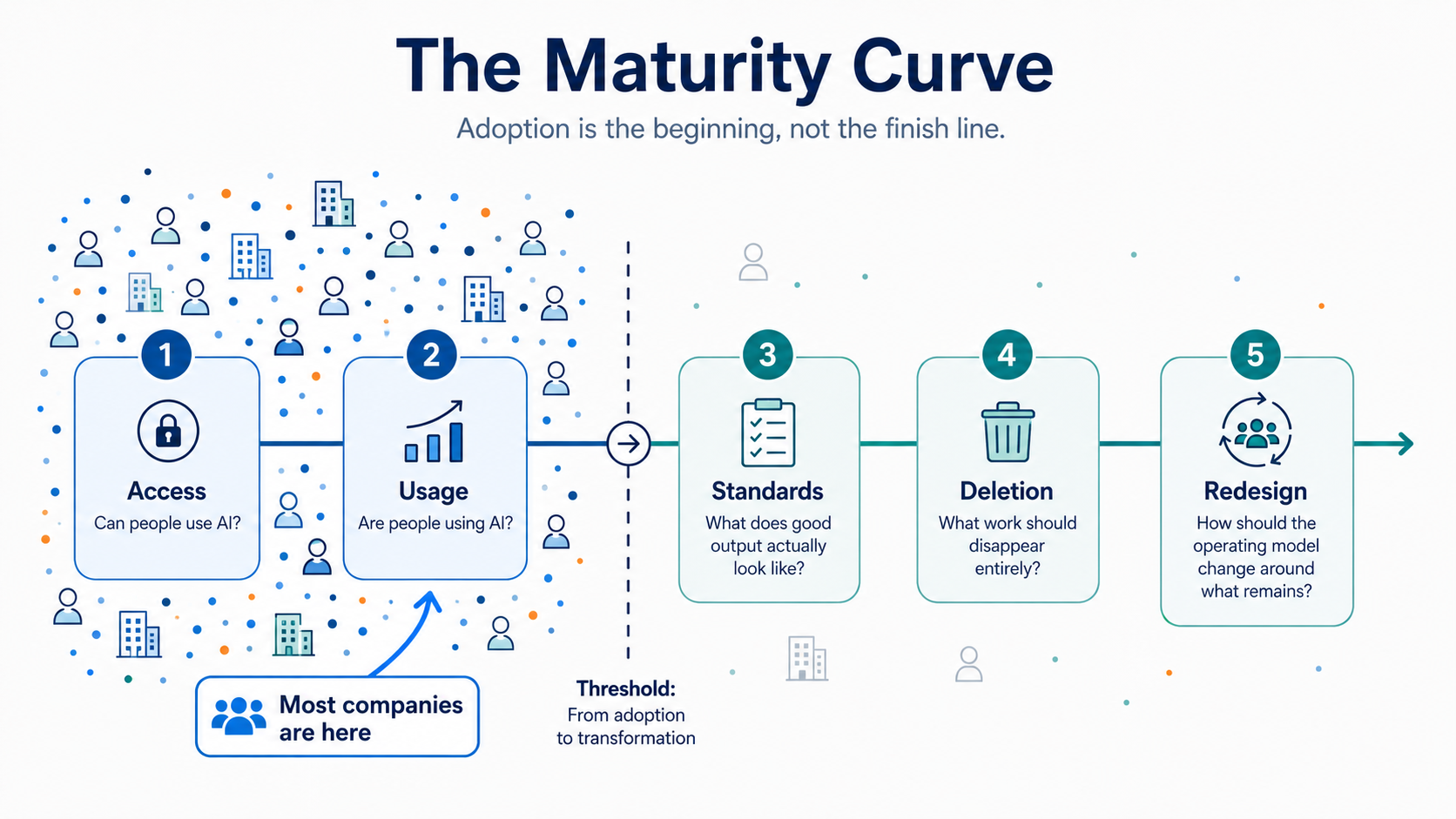
Phases 1 and 2 are necessary, but not sufficient. The error is treating Phase 2 adoption metrics as the destination rather than the entry point for harder questions. Most companies are here, and celebrating it.
The advantage begins at Phase 3, but getting there requires a deliberate shift: from exploration to selection, from generating to judging, from asking what AI can do to asking what deserves to be done at all.
The sequence looks like this: saturate to discover what is possible, observe where value actually appears rather than where it was expected, define standards for what good looks like in each context, delete low-value use cases explicitly rather than by neglect, and redesign workflows around decisions rather than tools.
Most organizations will stay comfortable in the exploration phase longer than is strategically wise, because exploration feels like progress and selection requires effort in discerning and identifying what did not work.
The first mistake is rationing AI too early. The second mistake is never rationing it again.
From access to discernment
AI saturation is a powerful search strategy, but exploration is not the same as an operating model.
The companies that win the next phase will be the ones that moved through the full maturity curve: from access to standards, from experimentation to deletion, from AI everywhere to AI where it actually changes the system.
Because when intelligence becomes cheap, the premium moves to judgment.